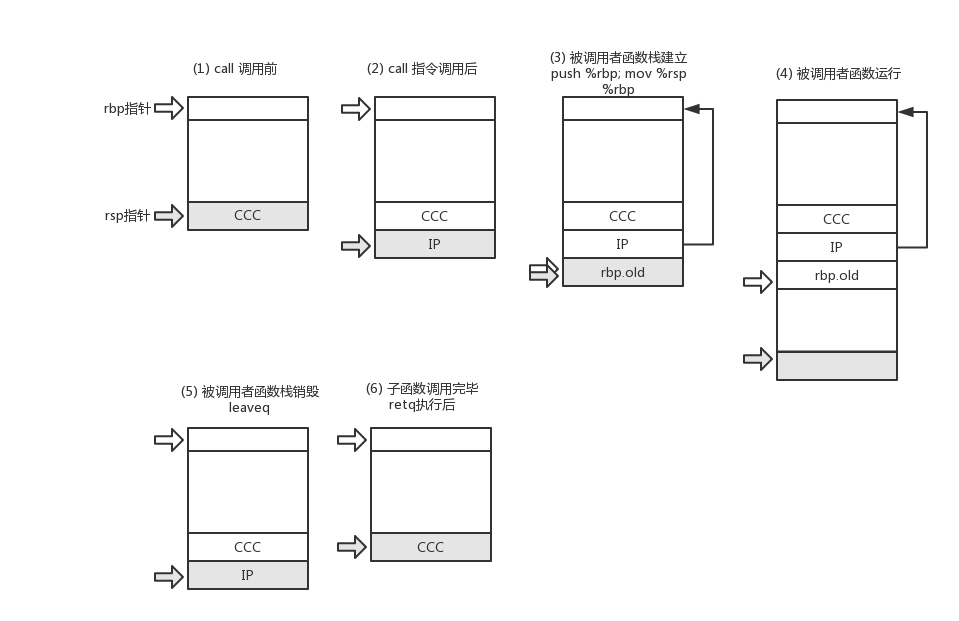
在众多的coredump中,有一类crash调试起来是最麻烦的,那就是“栈被破坏”导致的函数调用回溯结构破坏引发的coredump。本文,主要讲讲这一类crash的成因、原理以及调试方法。
1. SMTC(show me the code)
首先,让我们来看一段代码
1 | 1 #include <stdio.h> |
这段代码的关键在于fun函数会有递归调用,而在参数大于10的时候会导致写入的空间超过了栈上的“合法”内存。我们先来看下这段代码的输出
1 | The 8 step begin. |
对于输出,我们做简要的解释:
- 所有的栈上地址都是合法(此处的合法,指的是操作系统允许写入)的,也就是说即使写入到a[19]这样的非预期地址,也不会crash
- 由于栈的增长方向是高地址向低地址,而“写坏”的是“高地址”,也就是说已经申请过的地址。
- 栈上与函数调用最相关的数据信息是rip&&esp,而直接导致crash的原因是因为rip被“写坏”,导致执行对应的指令出现问题。
2.原因详细解释
首先,我们来回顾一下函数调用过程中的stack数据分布与变化(link)。接着看上文的程序输出就明白:在fun函数调用的末尾,需要执行ret指令,也就是说会将地址为rbp+8对应的栈上数据放入rip寄存器中,然后执行rip对应的这一条这令,这里现在是存放的是一个0~19的数字,不是一个合法的指令地址,于是产生了crash。
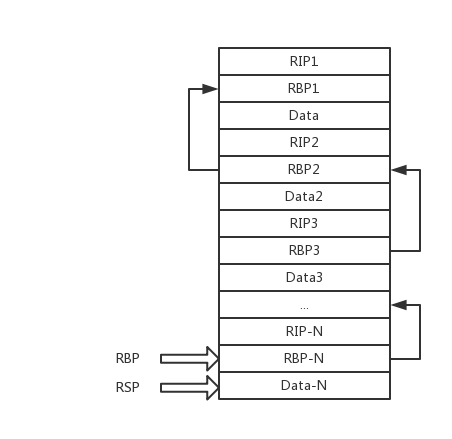
也就是说,正常情况下,ebp数据结合栈上的数据实际上构成了一个单向链表,链表头是当前执行的函数,往链表尾部,是对应在各个层次的调用者函数。stack上对应的函数调用链表如上图。看到这里我们可以得出结论:
1.stack crash 的本质是rbp&&rip的数据错乱导致。而具体crash的位置,取决于rbp和rip对应的数据。另一方面,栈上的数据错乱也不一定导致crash,有可能仅仅是把应该写入变量a的数据写到了变量b。
2.stack crash时,函数的执行已经脱离了出问题的函数。也就是说,A调用B,B函数中产生了栈上空间的错误写入,但是crash往往发生在A函数之中,因为只有B函数对应的汇编代码的最后一句retq执行完毕之后,才会发生crash,此时,程序的控制权在函数A之中。
3.stack crash时,函数调用栈已经被破坏。但是被破坏的是调用栈的头部。这也是唯一值得欣慰的信息了,函数调用栈尾部的信息依然完好无损。而我们可以据此,推测出函数调用的蛛丝马迹。
3.手动恢复函数调用栈
需要指出的是,被破坏的函数调用栈部分已经无法得到恢复了。此处我们能恢复的,仅仅是没有被破坏的部分。恢复函数栈的原理也很简单,那就是根据栈空间中的内存内容,找到那个“链表”即可。
继续使用上文我们对应的coredump文件,我们可以看到,由于函数调用最近的RBP对应的栈上内容已经被破坏,此时我们已经无法用bt指令得到正确的函数栈了。
1 | Missing separate debuginfos, use: debuginfo-install glibc-2.17-105.el7.x86_64 |
我们知道,函数调用栈在回溯过程中会执行两条关键的指令move %rbp %rsp; pop %rbp。而回溯行为对应的retq指令是在这两条指令之后执行的,此时rsp的值仍然是有效的。所以我们可以根据ESP的值打印出目前栈空间的数据。具体命令x/256xg 0x7ffd79ef9e40(rsp对应的值)和结果如下
1 | (gdb) info reg rsp |
这里,函数调用关系比较长,我们以栈开始部分的数据来说明。使用x/256xg 0x7ffd79ef9e40+0x100获取栈跳过rsp开始被写坏的部分数据,得到如下rbp对应的list
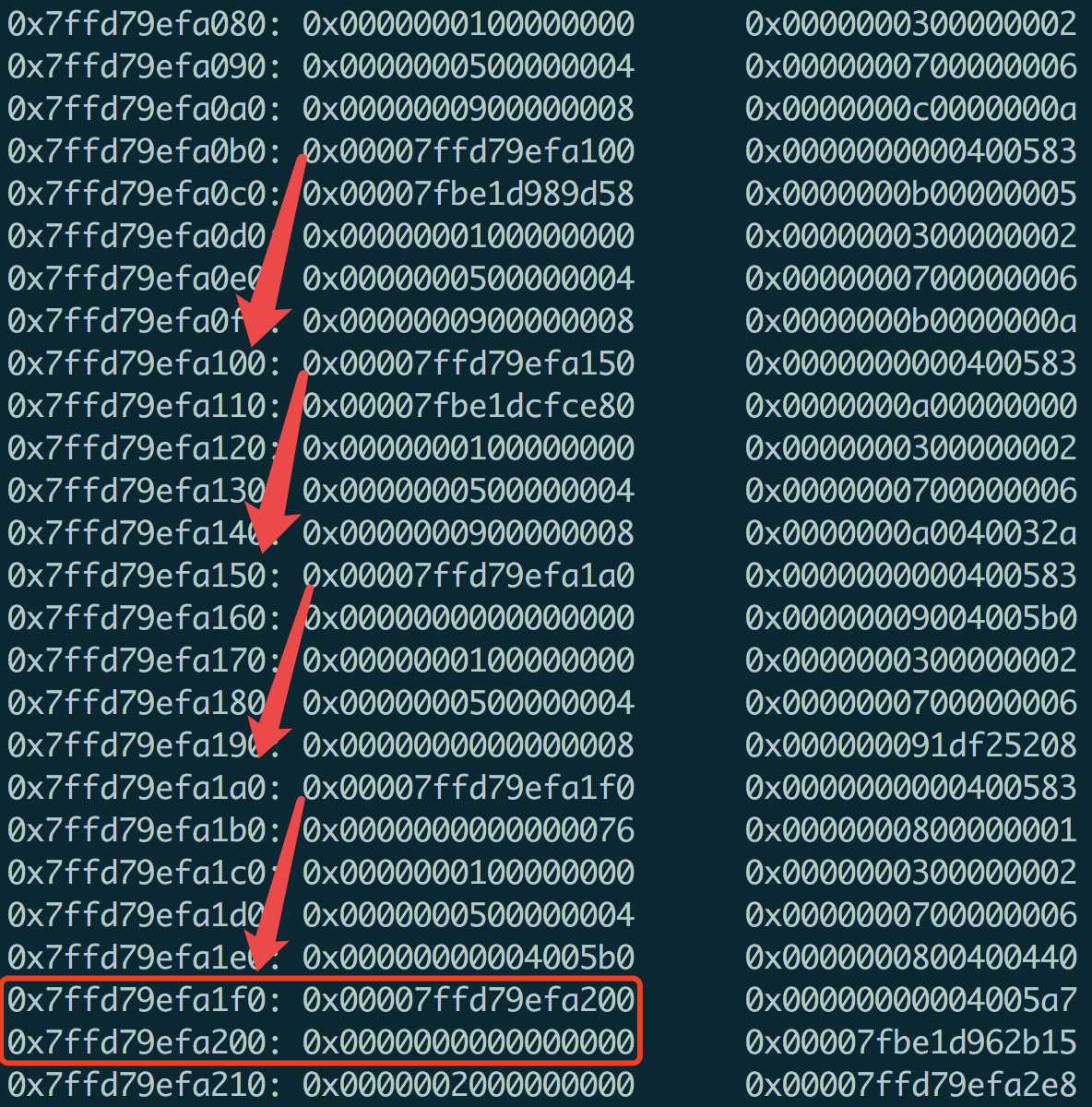
好了,此时,我们已经找到了这个list,那么如果通过这个list找到函数调用关系呢?
通过rbpList恢复函数调用关系
通过《从汇编语言看函数调用》这篇文章,我们已经知道,栈上和rbp相邻的位置,就是对应的rip的值。而知道了rip的值,就能知道对应的代码位置。具体操作如下。
通过上图,我们根据这个list得到对应的rip-list对应的地址(rbp + 8对应的内容)依次全部为 0x0000000000400583 >> 0x0000000000400583 > ... > 0x00000000004005a7, 如下图:
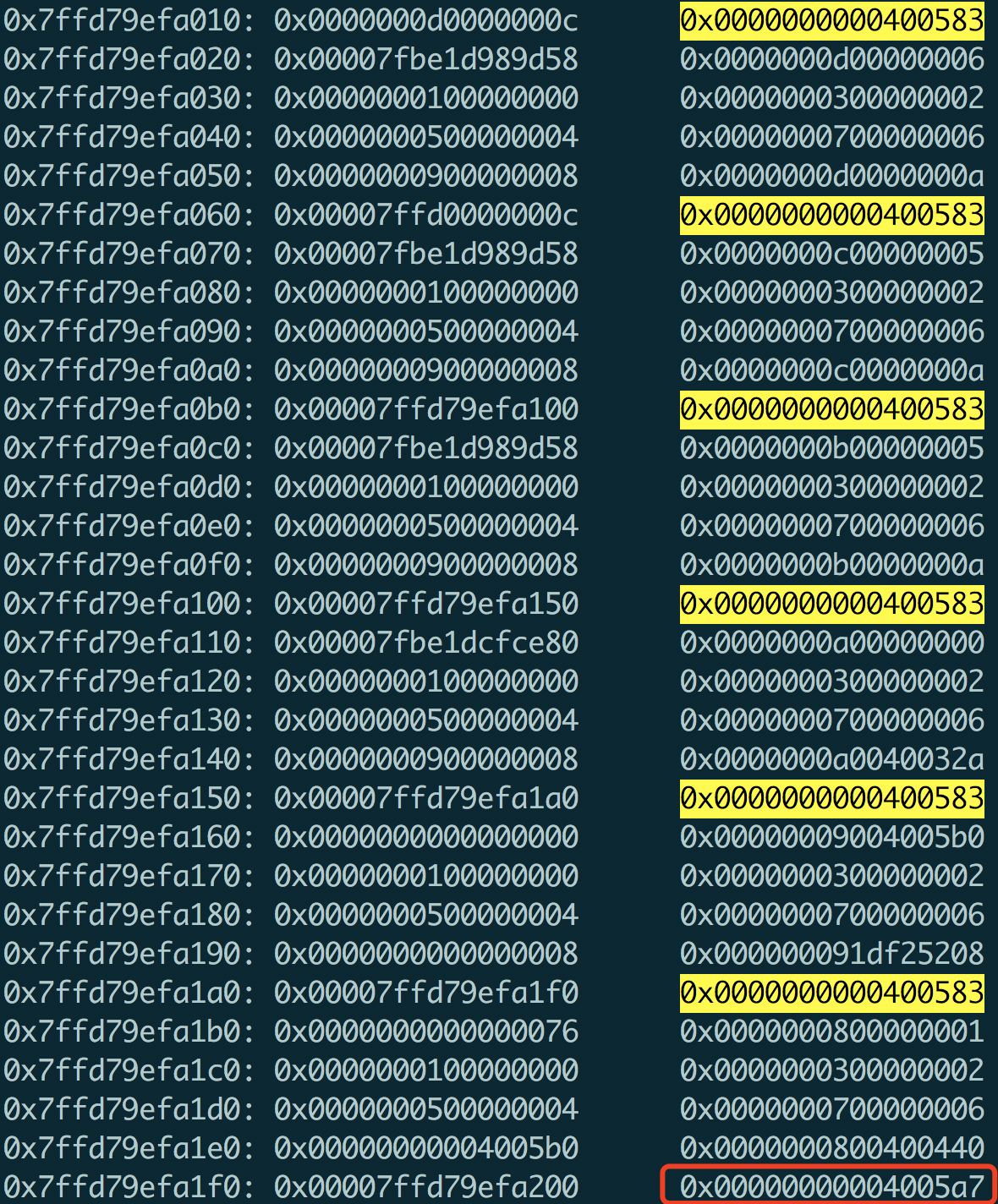
有了rip地址,接下来只需要找出该地址对应的代码位置即可。这里,我们可以使用addr2line工具来分析代码段地址对应的源代码位置,结果如下。
1 | [ykhuang@ykhuang-temp ~]$ addr2line -e test 0x0000000000400583 |
我们可以看到,这两个地址分别对应源代码的13和19行。 这里分别对应的printf和return 0对应的位置。实际上出问题的位置发生在这两行代码的上一行,因为rip对应的意义是下一条指令的地址. 至此,我们已经得到了部分函数调用关系。实际debug的过程中,这也几乎是我们能从一个crash的堆栈上能够获取的全部信息了。有了这部分信息,可以让我们迅速定位问题。当然,结合实际的代码,我们可以从stack中靠近rsp被写坏的数据是什么,来反推和代码的对应关系。
4.总结
“栈被写花”导致的crash虽然难以排查,但是我们还是能根据栈上仅存的信息,尽可能缩小“问题”代码所在的位置。这其中的原来就是函数调用过程中函数栈的建立和销毁过程。当然,除此之外,你需要熟悉一些基本的gdb指令(查看内存、反汇编、查看对应寄存器的值等),也需要了解一些汇编指令的实际含义。其实,对于这种crash,还有另外的方式能够保存函数调用栈,我们以后再展开讨论。在实际的生产中,由于crash文件比较大,对crash现场的保存往往采用保存函数调用堆栈的方式。但是这种情况下,函数堆栈是无意义的,所以保存一些栈上数据,有利于我们更快定位问题,毕竟stack空间本来就不大。